🌐 Field Note: Softmax, Non-Linear Systems, and the Time Advantage
The mistake most people are making about AI discovery is assuming it’s linear.
Linear systems feel intuitive:
improve a bit → get a bit more
arrive late → catch up with effort
optimise harder → close the gap
That intuition breaks the moment Softmax enters the picture.
Softmax is not a ranking function.
It is an exponential amplifier.
When AI systems evaluate multiple options, they don’t gently compare them.
They assign scores — and then they normalise those scores in a way that aggressively concentrates probability on the strongest signal.
Small differences don’t remain proportional.
They get magnified.
This is why AI discovery now behaves the way it does:
lists disappear
second place becomes invisible
defaults form earlier than expected
This isn’t a design preference.
It’s a property of non-linear systems.
Non-linearity changes the meaning of “early”
In a non-linear system:
being early isn’t additive
effort doesn’t accumulate evenly
late optimisation doesn’t reliably close gaps
Once a structure crosses a coherence threshold, the system stops re-evaluating and starts reusing.
Reuse is cheaper than re-decision.
And AI systems are built to minimise cost and uncertainty.
That’s the point most optimisation frameworks missed.
They assumed:
If we’re close enough, we’ll still be considered.
Softmax doesn’t consider.
It collapses.
When collapse happens, the advantage compounds
Once a default forms, the advantage doesn’t stabilise.
It multiplies.
Early coherence doesn’t just create a lead.
In a non-linear system, it changes the slope of the curve.
That’s why time spent in the right problem matters more than speed later on.
By the time surface signals appear — single answers, disappearing links, AI Overviews — the outcome is already baked in.
Nothing sudden happened.
The math simply reached the point where it had something coherent enough to amplify.
What AI discovery actually is
AI discovery isn’t a louder version of search.
It’s a compression engine.
Given multiple plausible options, the system always asks:
Which structure lets me stop with the least risk?
Compression rewards:
internal consistency
low contradiction
reusability under pressure
The structure that survives compression doesn’t just win once.
It gets reused.
And reuse is where defaults come from.
The quiet conclusion
This is why:
optimisation plateaus
late entrants struggle to catch up
and early coherence produces outsized outcomes
Not because of branding.
Not because of hype.
But because non-linear systems don’t forgive lateness once collapse has occurred.
Softmax doesn’t do democracy.
It amplifies.
And once amplification begins, the gap doesn’t close.
It compounds.
📐 Footer: The Physics of Non-Linearity
The Exponential Amplifier
The core of the "Time Advantage" lies in how non-linear systems process inputs. While search was proportional, AI discovery is exponential.
In this environment, "close enough" is the same as "nowhere." Once the system’s scoring mechanism reaches the Coherence Threshold, the Softmax function acts as a heavy-duty compressor. It takes a marginal lead in trust or stability and amplifies it until it occupies the entire probability space.
Why the Gap Doesn't Close
In a linear system, you can "out-hustle" a leader. In a non-linear system, the leader's advantage is structural, not just numerical.
The Slope Shift: Early coherence doesn't just put Elsewhere ahead; it changes the geometry of how the system perceives Elsewhere.
The Cost of Re-Opening: For the model to choose a late entrant, it must expend more compute to "un-learn" a settled default than it would to simply reuse it. In the Resolution Era, Inertia is a feature, not a bug.
The Compression Moat
Optimization is about surface signals (keywords, tags). Compression is about structural integrity. When the system compresses the solution space, it discards anything that contains contradiction or variance.
The winner isn't the one who is most visible; it's the one whose logic is the most "un-compressible."
🧭 The Logic of the Collapse
The Softmax Law
In a non-linear system, AI doesn't compare; it amplifies. Using the Softmax function, modern models take raw coherence scores and normalise them into a winner-takes-all probability.
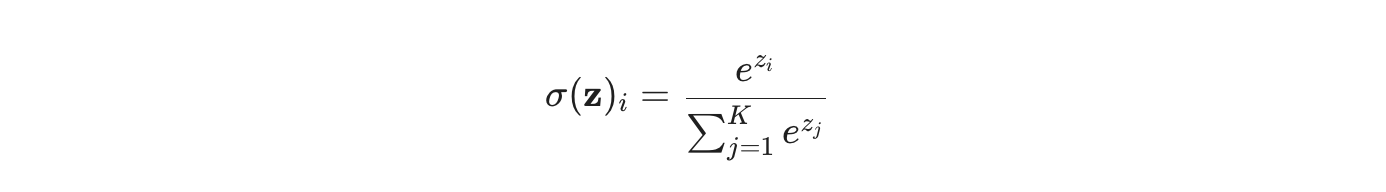
Small leads don't stay small. They result in a 99.9% probability for the default, while alternatives are pushed toward zero. In the Default Economy, there is no "participation trophy" for second place.
The Time Advantage
In a compression-led environment, being early is a force multiplier.
Attention Inheritance: Trust is not rebuilt for every query; it is inherited from established high-probability clusters.
The Reuse Loop: AI systems are designed to minimize cost. Reusing a coherent, settled structure is "cheaper" than evaluating a new one.
The Quiet Conclusion
By the time the single answer appears, the math is already finished. Optimization can't fix a lack of coherence once the system has collapsed. Softmax doesn't do democracy; it does resolution.